重新定义AI编码基准:SWE-Bench Pro 如何成为大模型的“真实战场”?
在人工智能飞速发展的今天,AI 编程智能体(AI Coding Agents)已经从简单的代码补全进化到了能够独立解决复杂 GitHub 问题的阶段。然而,随着模型能力的提升,如何科学、公正地评估这些智能体在现实软件工程环境中的表现,成为了行业迫切需要解决的难题。近期,SWE-Bench Pro 的发布为这一领域确立了新的“金标准”。
为什么传统的基准测试不再够用?
在此之前的 SWE-Bench 等基准测试虽然极大地推动了行业进步,但也面临着严峻的挑战。SWE-Bench Pro 的研发团队指出,旧有评估体系存在四个核心痛点:
- 数据污染:模型可能在训练阶段已经“背过”了测试代码,导致其表现更像是记忆而非解决问题。
- 任务多样性受限:多数基准测试集中在简单的实用库,无法覆盖现实世界中复杂的软件挑战。
- 过度简化的痛点:许多模糊或未明确定义的问题被剔除,而这恰恰是开发者日常工作中必须面对的现实。
- 不可靠的测试环境:环境配置的不一致导致难以判断解决方案是否真的有效。
SWE-Bench Pro:更严苛、更真实、更智能
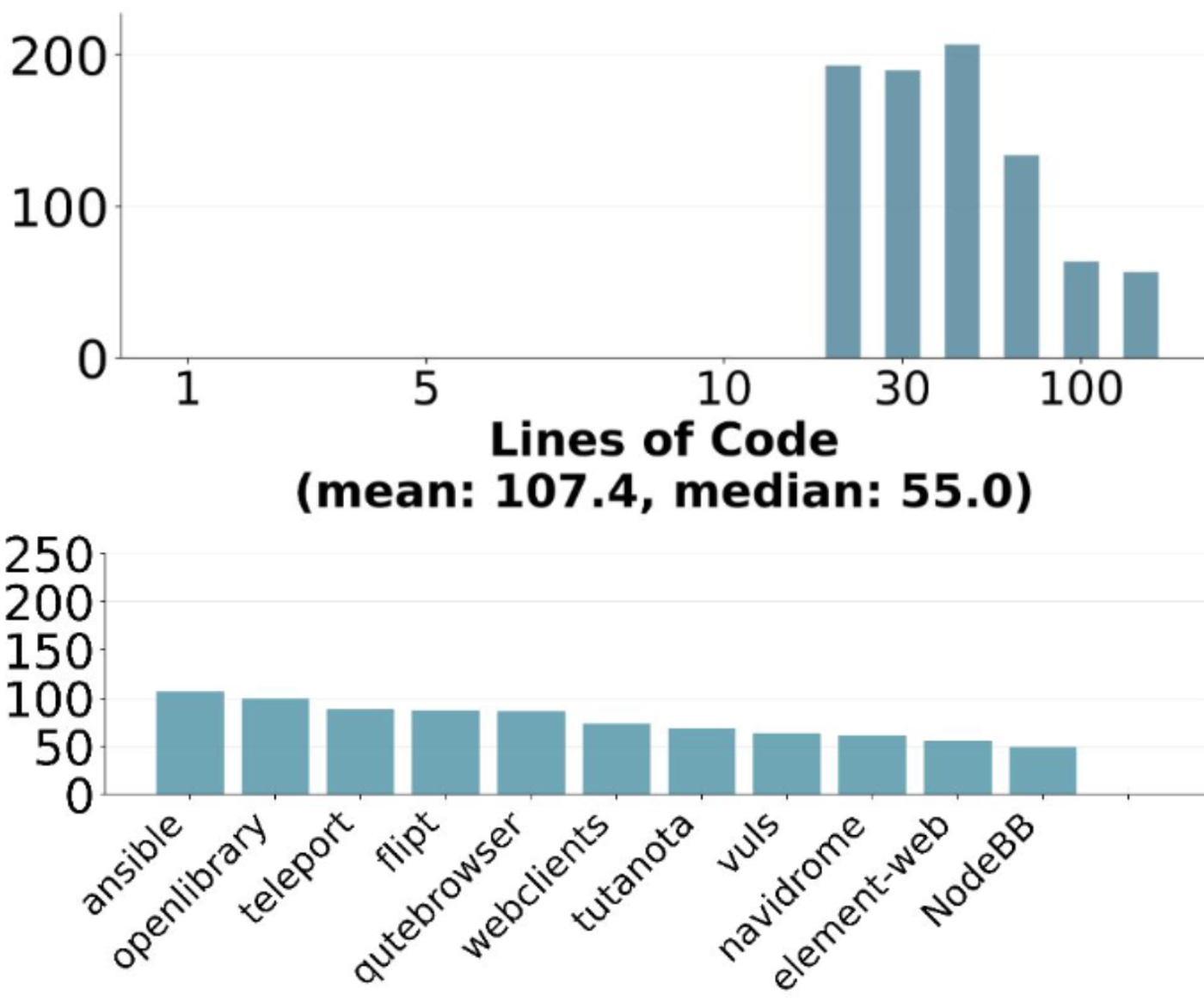
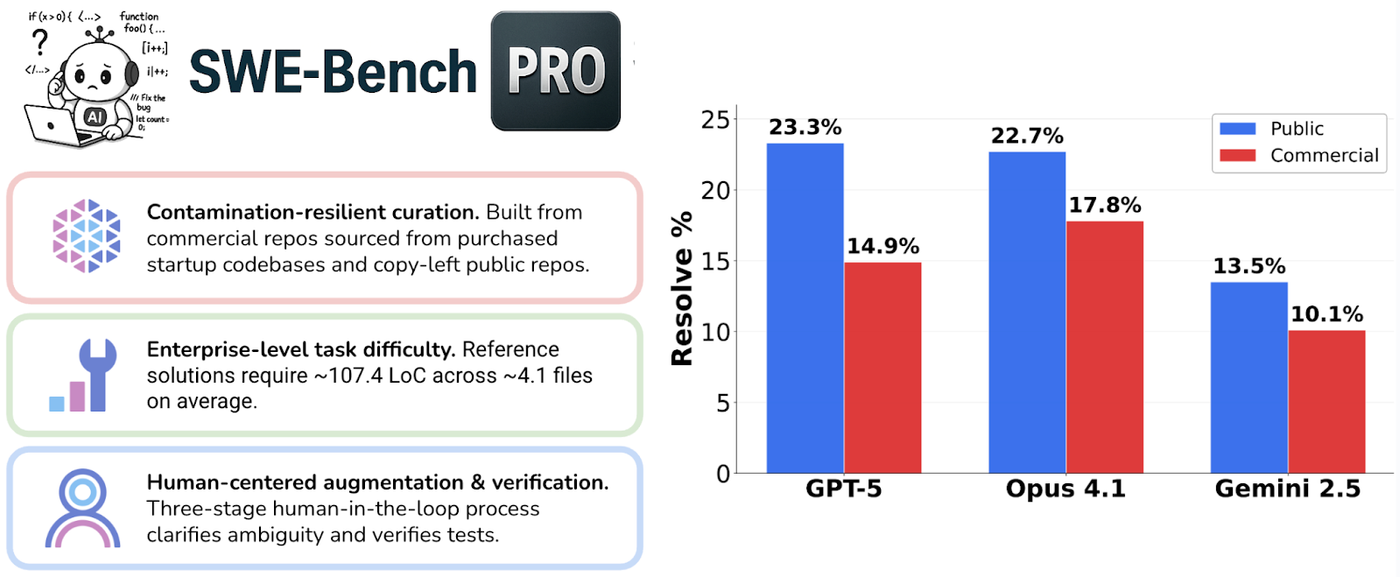
为了应对这些挑战,SWE-Bench Pro 引入了多项创新机制。它不仅从多样化的代码库(包括 B2B 服务、开发工具和初创公司的专有代码)中提取任务,还采用了强 Copyleft 许可证(如 GPL)的开源子集和完全不公开的私有子集,从设计之初就杜绝了数据污染的可能性。
四阶段严格构建流程
每个问题的创建都经过了极其严谨的流程:
- 资源搜寻:精选具有代表性的公共和私有仓库。
- 环境创建:专业工程师构建可重复的 Docker 镜像,确保环境“开箱即用”。
- 任务提取:通过 commit 抓取,确保问题包含修复前后的对比测试。
- 人类专家增强:由人类专家整理问题说明,确保在不提示实现方案的前提下,提供足够的上下文供 AI 解决问题。
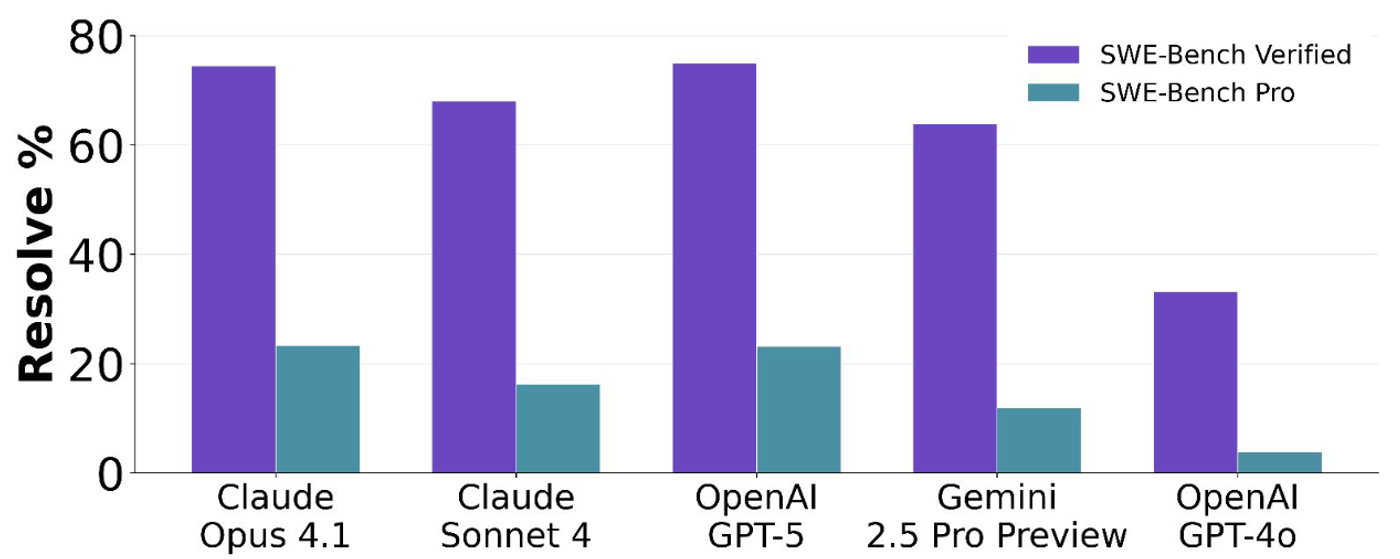
榜单大地震:从 70% 到 23% 的断崖式下跌
SWE-Bench Pro 给当前最强的 AI 模型们来了一场“降温”。在 SWE-Bench Verified 版本中,顶级模型的解决率(Resolve Rate)通常能达到 70% 以上,但在更具挑战性的 Pro 公共数据集中,GPT-5 和 Claude Opus 4.1 等顶尖模型的得分仅为 23% 左右。
关键洞察:
- 私有代码库是终极考验:在完全未见的私有子集中,模型表现进一步下滑。例如,Claude Opus 从 22.7% 跌至 17.8%,这表明模型在泛化能力上仍有巨大的提升空间。
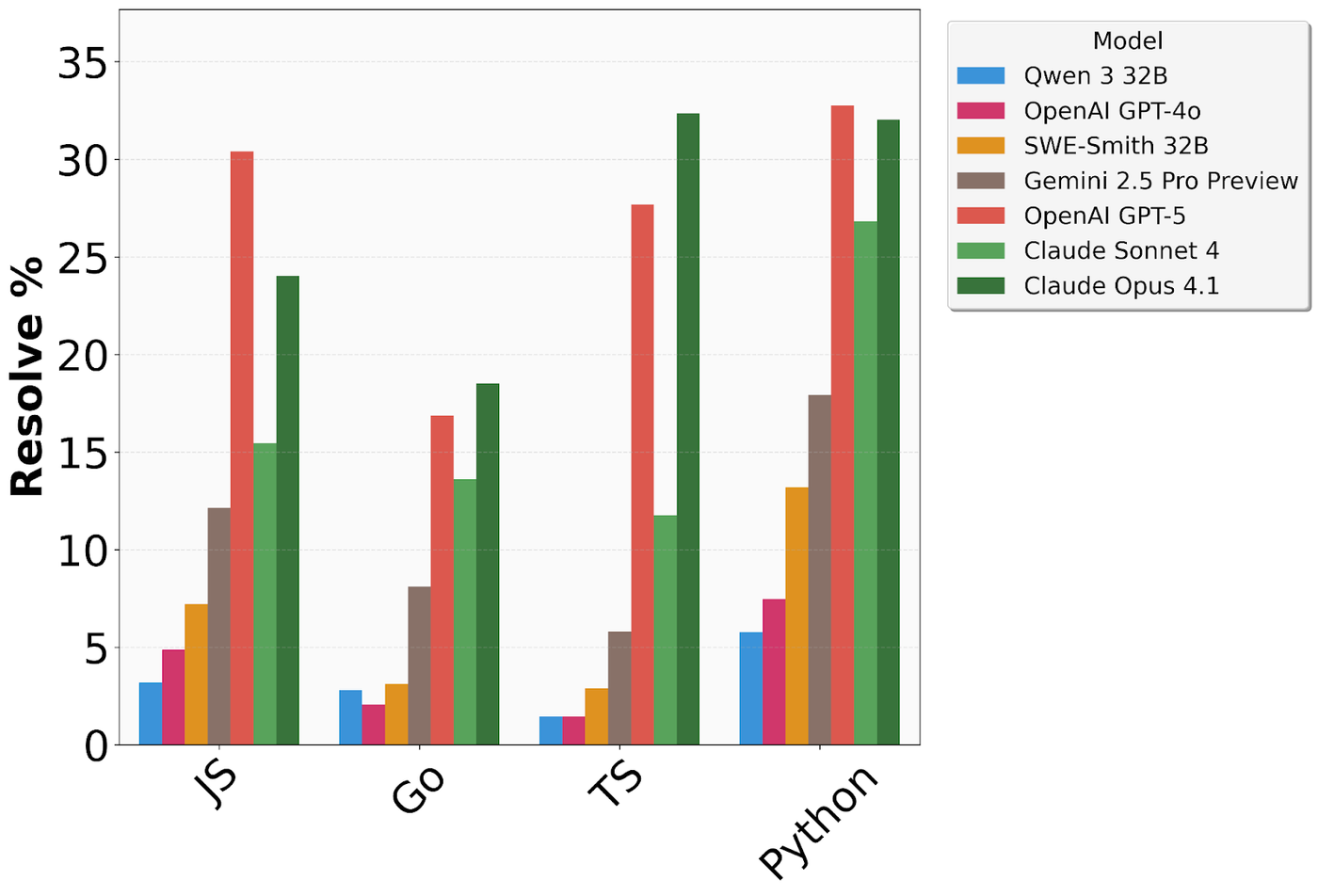
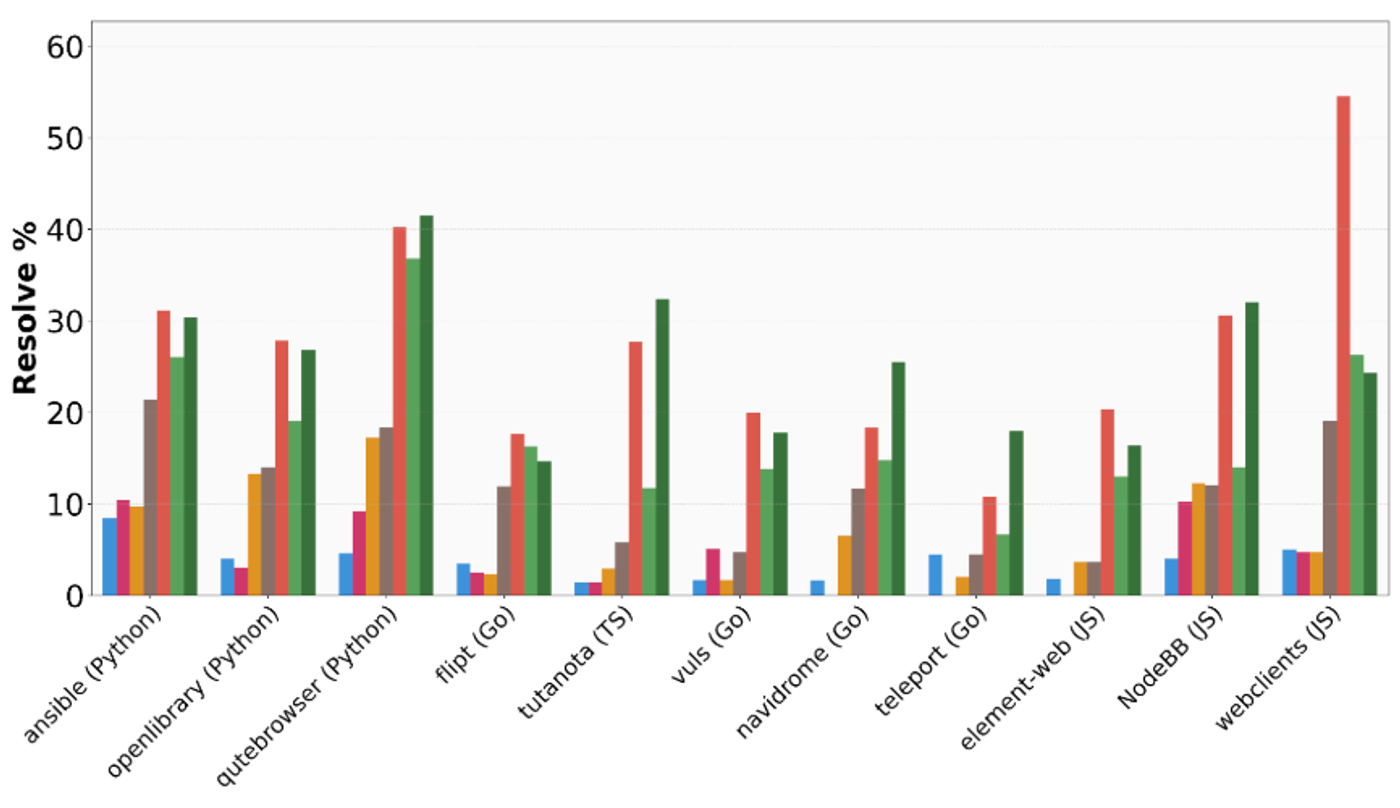
- 编程语言的差异性:AI 在 Python 和 Go 语言上的表现相对较好,但在 JavaScript 和 TypeScript 上则表现出极大的不稳定性,解决率波动剧烈。
- 稳定性与一致性:GPT-5.4 和 Claude 系列展现了更强的稳定性,而较小的模型则表现得非常“偏科”,在某些仓库中表现尚可,在另一些仓库则完全束手无策。
Qwen 3 的崛起:中国力量在国际榜单的表现
在最新的榜单中,来自阿里巴巴的 Qwen3-coder-480b 表现亮眼,以 38.7% 的解决率位列前茅,超过了许多国际知名的闭源模型。这标志着 Qwen 系列在处理长序列任务和复杂软件逻辑重构方面的能力已跃升至世界第一梯队。
Qwen Studio 提供的全方位功能——包括图像/视频理解、文档处理和强大的工具利用能力,为其在解决需要跨文件理解和复杂环境交互的软件工程任务时提供了坚实支撑。
结论:迈向真正的自主软件工程
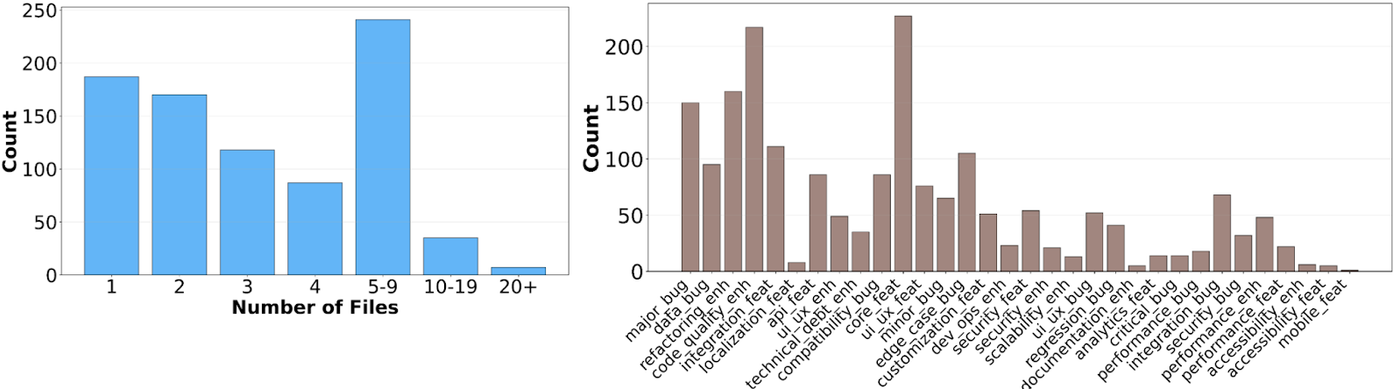
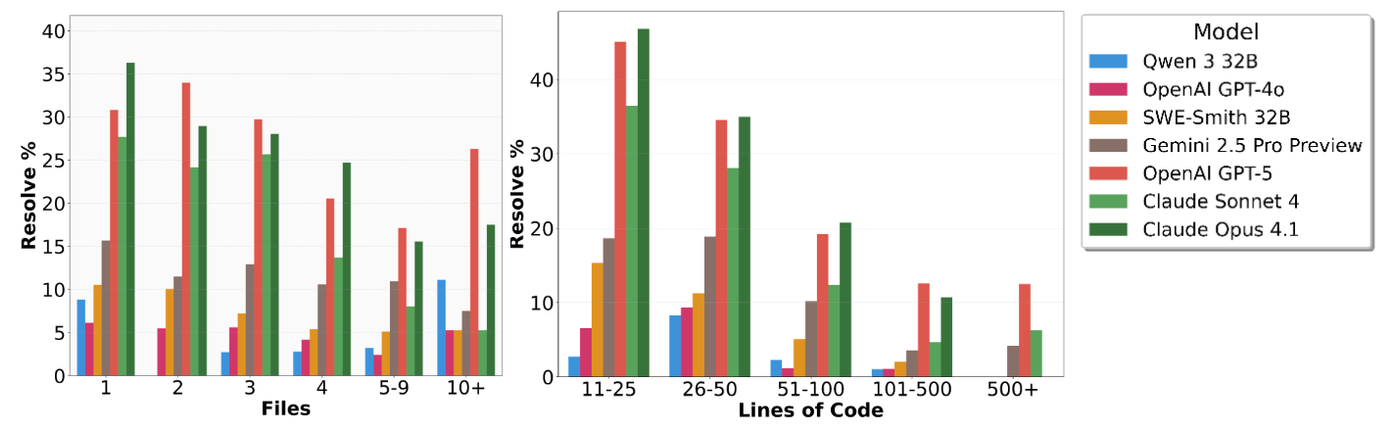
SWE-Bench Pro 的出现揭示了一个事实:虽然我们已经取得了长足进步,但距离 AI 能够完全替代人类进行复杂软件维护还有很长的路要走。随着问题复杂度的增加(涉及更多文件修改和更多行数变更),所有模型的表现都会显著退化。
对于开发者而言,这不仅是一个评估工具,更是一个指路明灯。它告诉我们,未来的 AI 编程不仅仅是生成代码片段,更是关于如何在庞大的代码迷宫中进行逻辑推理、环境感知和持续学习。