Claude Opus 4.7 深度解析:编程智能体的新标杆,及其背后的“隐形成本”
2026 年 4 月 16 日,Anthropic 正式推出了其当前最强大的通用模型 —— Claude Opus 4.7。这次更新不仅是性能的迭代,更是针对“编程智能体”(Coding Agents)的一次重大进化。

性能狂飙:重新定义编程基准
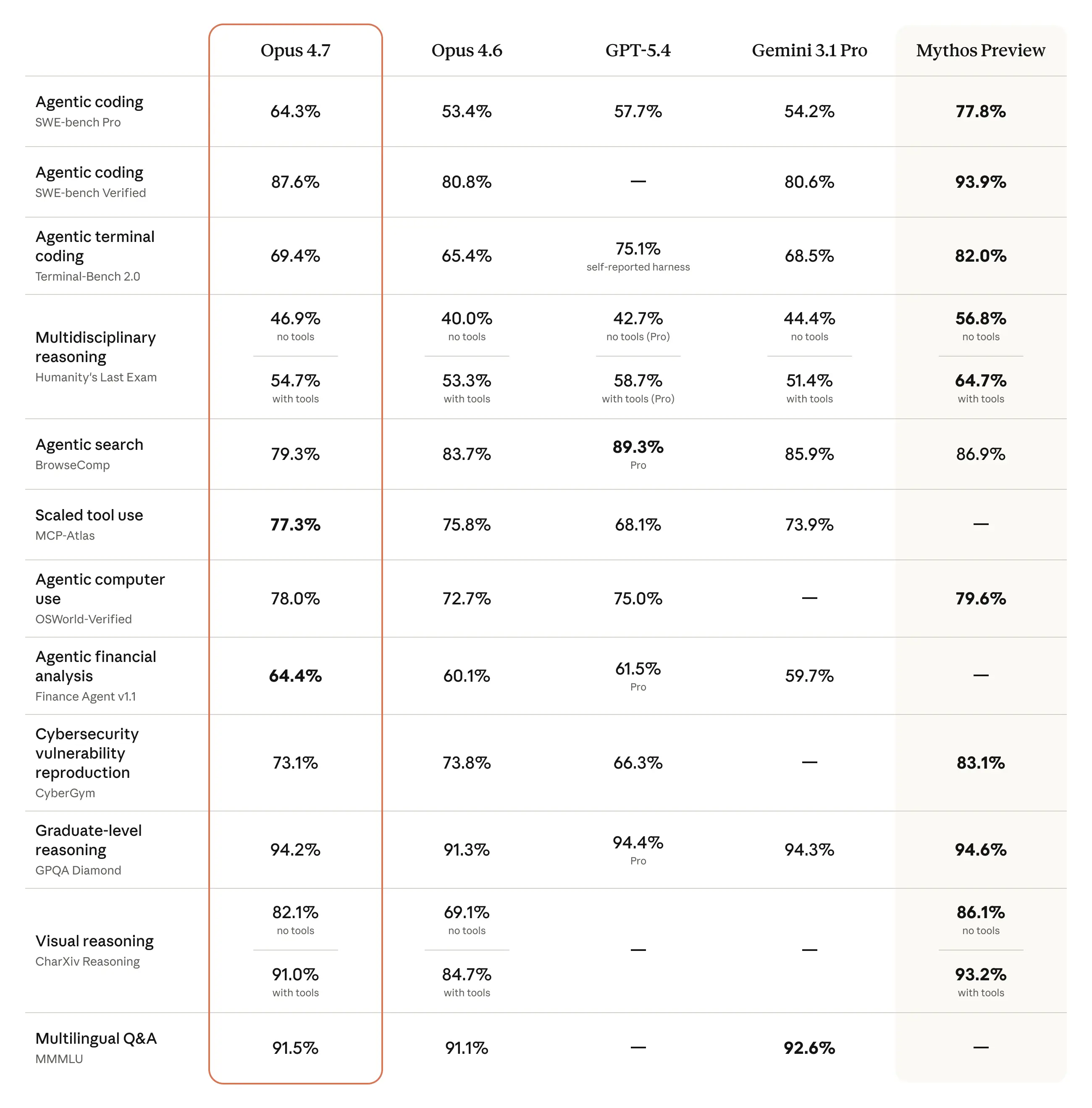
Claude Opus 4.7 的核心亮点在于其在复杂软件工程任务中的卓越表现。根据官方及合作伙伴的评测数据,Opus 4.7 在多个权威基准测试中实现了跨越式增长:
- SWE-bench Verified: 从 80.8% 跃升至 87.6%。
- CursorBench: 成功率从 58% 提高到 70%。
- GPQA Diamond: 达到 94.2%,在逻辑推理层面已触及目前 AI 的天花板。
这意味着在处理真实世界的 GitHub 问题或复杂的代码库重构时,Opus 4.7 的可靠性显著增强。CodeRabbit 的报告指出,该模型在处理复杂 PR(拉取请求)时的召回率提升了 10% 以上,且保持了极高的精准度。
编程智能体的四大关键变革
1. 自我校验行为(Self-verification)
Opus 4.7 不再只是被动输出代码,它开始学会“先检查,后汇报”。在 Agent 模式下,模型会主动编写测试、运行测试并修复失败项,最后才向调度器提交结果。这种行为改变极大地减少了“一本正经胡说八道”的概率。
2. 新增 "xhigh" 努力级别
在原有的 low、medium、high、max 基础上,Anthropic 引入了全新的 xhigh 级别。这是专为编程和 Agent 用例设计的平衡点。实验证明,Opus 4.7 在 low 级别下的表现已接近 Opus 4.6 的 medium 水平。
3. 视觉能力大幅提升
模型处理图像的最大分辨率从 1.15 MP 提升至 3.75 MP。对于计算机自动化操作(Computer Use)而言,这意味着模型可以直接识别屏幕上的像素坐标,无需再进行缩放校准。其在 XBOW 视觉精准度测试中从 54.5% 暴涨至 98.5%。

一个必须要警惕的“坑”:分词器变动与真实成本
尽管 Anthropic 维持了 $5/M 输入和 $25/M 输出的报价,但你的账单可能会增加。原因在于 Tokenizer(分词器) 的更新。
Opus 4.7 使用了新的分词方式,对于相同的文本,生成的 Token 数量会增加 1.0x 到 1.35x。这意味着:
- 英文散文: 影响较小(约 1.05x)。
- 结构化数据 (JSON/XML): 增加约 1.1x - 1.2x。
- 多语言文本 (如中日韩文): 影响最大,Token 数可能增加 20% - 35%。
换句话说,对于中文用户,虽然单价没变,但实际支付成本可能上涨了 30% 以上。
竞争格局:Opus 4.7 真的无敌了吗?
虽然 Opus 4.7 在 SWE-bench 上表现亮眼,但在其他细分领域,竞争对手依然保持着压力:
- 命令行操作 (Terminal-Bench 2.0): Opus 4.7 得分为 69.4%,落后于 GPT-5.4 的 75.1%。
- 网络研究 (BrowseComp): Opus 4.7 出现了 4.4% 的回退(79.3%),而 Gemini 3.1 Pro 和 GPT-5.4 依然处于领先地位。
- LiveCodeBench: 根据 PricePerToken 的最新榜单,Gemini 3 Pro Preview 以 91.7% 的高分领跑,Opus 系列仍需在算法竞技类题目上发力。
总结与迁移建议
Claude Opus 4.7 无疑是目前最适合构建“自动驾驶式”编程 Agent 的模型。它更聪明、更细心、视觉更敏锐。然而,迁移时需注意以下几点:
- 处理 Breaking Change: Opus 4.7 不再支持 Assistant 消息预填(Prefilling),如果你的 Prompt 依赖此功能,需重新调整。
- 预算控制: 启用全新的
task-budgetsBeta 协议,为 Agent 循环设置 Token 上限,避免因模型“思考过度”导致成本失控。 - 关注 Mythos Preview: Anthropic 确认存在更强的 Claude Mythos 模型,但目前仅限于 Project Glasswing 合作伙伴。对于大多数开发者,Opus 4.7 就是你能买到的最强生产力工具。
无论你是追求极致代码质量的开发者,还是正在构建多 Agent 系统的工作流专家,Opus 4.7 都是 2026 年不容错过的选择。