
AI 代码生成的“信任墙”:回归“两遍编译器”架构,解决生产环境 43% 的报错危机
引言:当“确定性”遇上“随机性”
如果你是在 20 世纪 90 年代或 21 世纪初开始从事软件开发的,你一定记得“确定性”带来的那种快感:你写下代码,编译器分析、优化并输出精准的机器指令。同样的输入,永远得到同样的输出。
然而,随着大语言模型(LLM)的降临,代码生成几乎在一夜之间变成了一个随机过程(Stochastic Process)。相同的提示词,AI 可能给你截然不同的结果——有时惊艳,有时却隐藏着致命的 Bug。

现状:43% 的 AI 代码在生产环境中崩了
根据 Lightrun 发布的《2026 年 AI 驱动工程报告》,AI 代码生成的繁荣背后隐藏着巨大的信任危机:
- 高失败率:43% 的 AI 生成代码在通过 QA 和预发测试后,依然在生产环境中需要手动调试。
- 效率税:开发者现在平均每周要花 38% 的时间(约两天) 来调试、验证和处理 AI 留下的“烂摊子”。
- 调试困局:88% 的组织表示,验证一个 AI 建议的修复方案需要 2 到 3 次重新部署。
亚马逊在 2026 年 3 月发生的严重宕机事件就是一个警示。由于 AI 辅助的代码更改在未经充分批准的情况下部署,导致数百万订单损失。这证明了:虽然 AI 提升了写代码的速度,但现有的验证系统已经跟不上 AI 犯错的速度了。

救星:回归 1970 年代的“两遍编译器”架构
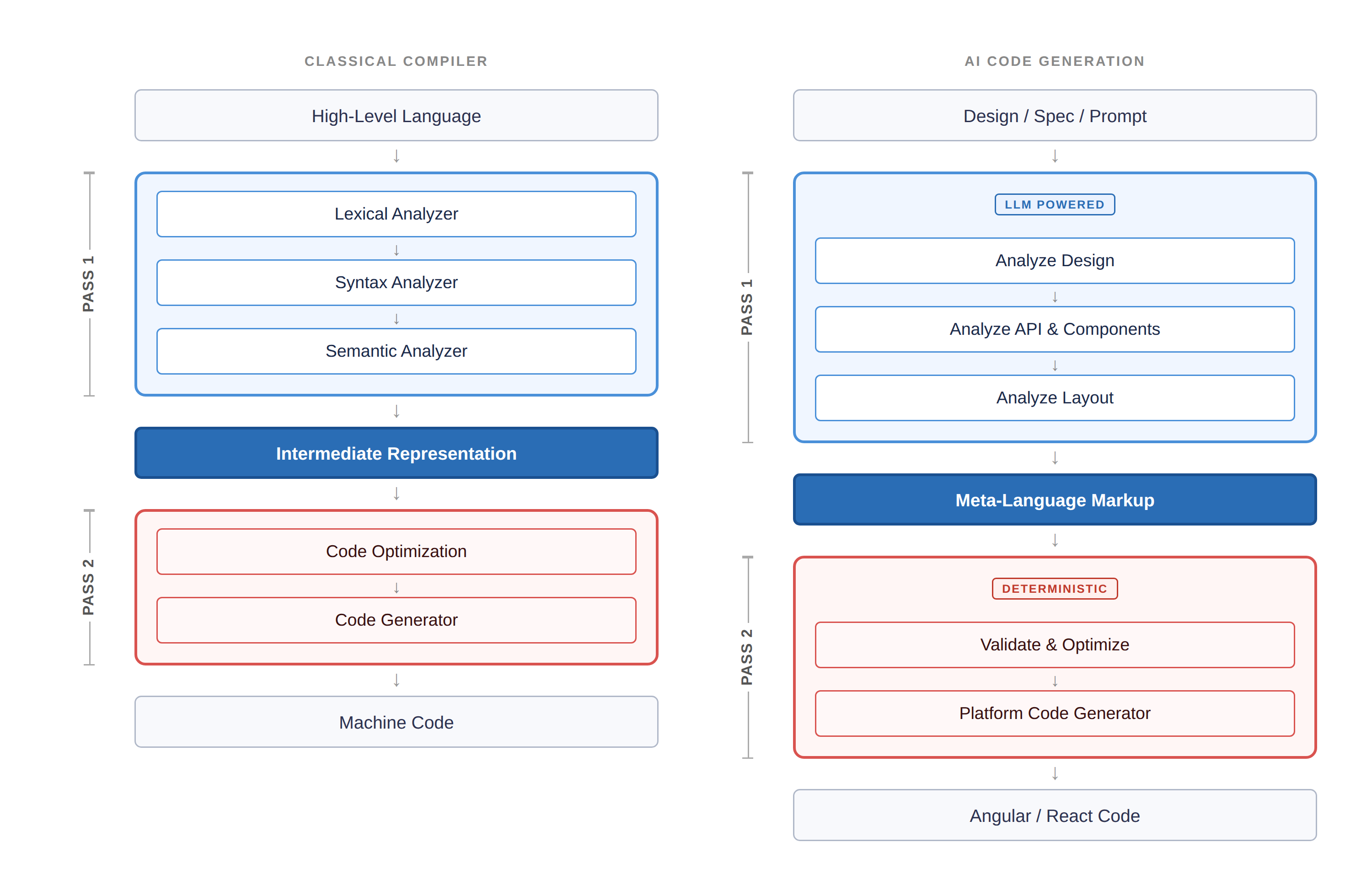
面对 LLM 的不可预测性,业界开始向计算机科学的基石寻求解法——两遍编译器(Two-pass Compiler)。早期的编译器是单遍的:读取源码、输出机器码,风险极高。而两遍编译器通过解耦“分析”与“生成”,彻底改变了工程质量。
这种架构被重新引入 AI 代码生成领域,将其分为两个截然不同的阶段:
第一遍(Pass 1):LLM 负责意图理解(随机性)
在这一阶段,LLM 发挥其长处:理解自然语言指令、分解设计需求。但它不直接输出成品代码(如 React 或 Java),而是输出一种中间表示(IR)——一种定义良好的元语言。由于输出受到结构化约束,AI 无法注入恶意的 script 标签,也无法幻觉出不存在的框架 Hook。
第二遍(Pass 2):确定性生成器负责输出(确定性)
这一阶段完全没有 AI 参与。一个确定性的代码生成平台读取验证过的中间表示(IR),并根据预设的生产规范,生成工业级的代码。同样的 IR 进来,永远输出同样的生产代码。
2026 年的开发新常态:从“提示词”到“智能体”
随着 Anthropic 的 Claude Code、OpenAI 的 Codex 和 Google Gemini 的竞争白热化,开发者的角色正在发生深刻变化:
- 氛围编程(Vibe Coding):像 Andrej Karpathy 所说,开发者有时只是在观察、沟通和拷贝,代码就“莫名其妙”地跑通了。这降低了开发门槛,让“开发者”群体从几百万扩展到了几亿人。
- 从工具到智能体:AI 不再只是自动补全的插件,而是变成了能够自主推理、决策并执行部署的 AI Agent。例如,Claude Code 宣称可以处理 100% 的代码编写,而人类则转向战略性的审计角色。
- 信任墙与运行时可见性:为了打破信任僵局,业界急需“运行时可见性”。只有当 AI 能够实时观察代码在生产环境中的运行状态,而不是“盲目”生成代码时,真正的自动化运维(AIOps)才能实现。
结论:工程纪律的回归
AI 模型很强大,但围绕它们的架构往往过于幼稚。修正 AI 错误的方法不是等待更聪明的模型,而是应用我们一直熟知的工程纪律。
正如 WaveMaker CEO Vijay Pullur 所说:“确定性工程再次变得酷了起来。”两遍编译架构并非只是为了优化,它是一种工程哲学:分离理解与生成,在输出前验证。
在这个 AI 生成代码无处不在的时代,未来的赢家将是那些既能拥抱 AI 的灵光一现,又能通过架构手段确保系统稳定性的团队。机器学会了写代码,现在,我们需要教它们学会如何像资深工程师一样思考和观察。