永恒的十一月:当大语言模型撞击开源社区的文化冰山
永恒的十一月:当大语言模型撞击开源社区的文化冰山
站在2026年4月的节点回望,软件开发领域正经历着一场前所未有的范式转移。随着本地大语言模型(LLM)技术的爆发,开源社区不仅在技术层面更新换代,在文化层面也正面临着自1993年“永恒九月”以来最大的冲击。我们将这一现象称为——“永恒的十一月”。
历史的重演:从“永恒九月”到“永恒十一月”
1993年,Usenet(早期的互联网讨论组)经历了著名的“永恒九月”。当时,由于AOL开始向其庞大的用户群提供Usenet访问权限,导致大量不懂网络礼仪的新手涌入,永久性地改变了互联网早期的精英文化。
而2025年11月(Opus 4.5发布之月)被公认为现代开发的转折点。从那时起,生成式AI编码工具实现了跨越式的进步,带来了一波完全依赖LLM的新开发者。软件自由保护协会(SFC)的 Denver Gingerich 指出,这些新手往往不熟悉自由及开源软件(FOSS)的传统文化,甚至在不知不觉中提交了大量的“AI垃圾代码”(AI Slop)。
“AI垃圾代码”:挑战还是机遇?
目前的开源维护者们普遍感到焦虑。大量由AI生成的 Pull Request(PR)质量参差不齐,有的甚至是致命的错误。然而,SFC呼吁老一辈开发者保持耐心。
维护者的策略建议:
- 从排斥转向教育:不要简单地拒绝AI生成的PR,而是将其视为教育新人的机会。正如早年的新手会写出拙劣的手写代码一样,现在的AI垃圾代码也是一种“原材料”。
- 引导建立私有分支:如果新手的修改仅对自己有用,应鼓励他们建立私有分支而非强行合并到上游。
- 保持沟通:识别那些真正愿意学习并改进工作流的新人,他们将是未来开源社区的新生力量。
![]()
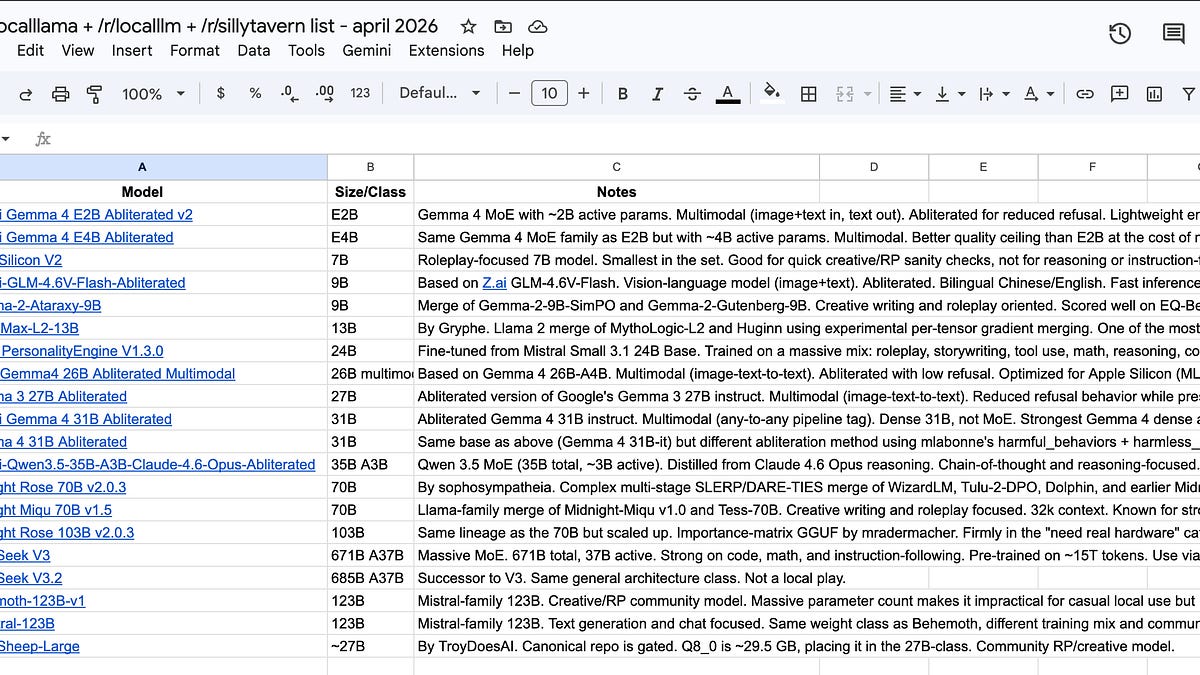
2026年4月:顶级本地大模型盘点
为了更好地融入现代开发工作流,了解并使用高效的本地模型至关重要。根据 Latent.Space 的最新调研,2026年4月的本地模型市场呈现出百花齐放的态势:
1. 全能型标杆:Qwen 3.5
目前社区中最广泛推荐的模型家族。无论是逻辑推理、日常对话还是复杂指令遵循,Qwen 3.5 都展现出了极强的统治力。
2. 本地部署首选:Gemma 4
由Google推出的这一代模型在中小规模部署中表现惊人,尤其适合在个人工作站上流畅运行,是本地可用性的典范。
3. 最强开源权重的竞争者:DeepSeek V3.2
DeepSeek 依然稳居第一梯队。作为最强的通用型开源权重模型之一,它在处理复杂通用任务时具有极高的性价比。
4. 编码专用王牌:Qwen3-Coder-Next
对于开发者而言,这几乎是唯一的共识选项。在本地编码辅助领域,该模型的效果已经超越了大多数通用模型。
5. 智能体与工具链:MiniMax M2.5 / M2.7
在处理需要频繁调用API或执行复杂工具链(Agentic workloads)的任务时,MiniMax 表现出了极高的鲁棒性。
结语:在技术浪潮中重构开源精神
“永恒的十一月”并非终结,而是一个新时代的开端。虽然“AI垃圾代码”带来的噪音令人疲惫,但正如1993年的Usenet最终适应了AOL用户的涌入,2026年的开源社区也将通过教育、协作和更先进的本地AI工具,吸收这股新力量。
开源精神的核心从来不是“排外”,而是“协作”。面对AI浪潮,我们不仅要升级手中的工具(如拥抱 Qwen 或 DeepSeek),更要升级我们构建社区的方式。让我们以更优雅、更包容的姿态,迎接这数十亿潜在的新开发者。