2026 AI 编程模型深度评测:从 SWE-bench 到 SWE-bench Pro,谁才是最强 AI 程序员?
引言:AI 编码从“补全”走向“自主解决问题”
就在不久前,我们还在惊叹于 AI 能够自动补全一行代码。而到了 2026 年,AI 模型已经开始作为“自主代理”直接处理 GitHub 上的复杂 Issue、修复 Bug 并实现新功能。为了衡量这些 AI 代理的真实水平,SWE-bench 及其衍生榜单成为了业界公认的“炼金石”。
本文将基于最新的 SWE-bench 数据和 Scale AI 发布的 SWE-bench Pro 基准,深度解析当前顶尖 AI 模型的编码实力对比。

1. SWE-bench 家族:多元化的评估维度
SWE-bench 不仅仅是一个单一的测试集。为了更精准地评估不同阶段的 AI 能力,它分化出了多个版本:
- SWE-bench Verified: 经过人类专家过滤的 500 个实例,去除了测试噪声,是目前衡量前沿模型(Frontier Models)的主战场。
- SWE-bench Lite: 经过筛选的轻量级子集,旨在提供更低成本、更快速的评估反馈。
- SWE-bench Multimodal: 引入了视觉元素,要求 AI 能够理解 UI/UX 相关的问题描述。
- SWE-bench Multilingual: 涵盖 9 种主流编程语言,评估 AI 的跨语言工程能力。
根据 2026 年 Onyx AI 的最新排名,Claude Opus 4.6 和 GPT-5.4 在这些传统榜单上已经达到了 70%-90% 左右的极高解决率,这意味着我们需要更难的“考卷”。
2. SWE-bench Pro:揭开“模型背题”的假象
随着模型参数规模的扩大,数据污染(Data Contamination) 成为了一个不可忽视的问题。模型可能在训练阶段已经“读过”了测试集中的代码,导致其得分偏高。为此,Scale AI 推出了 SWE-bench Pro。
为什么 Pro 版本更具权威性?
- 防止污染设计:主要采用 GPL 等强传染性开源协议的代码,以及从未公开过的企业私有代码库。
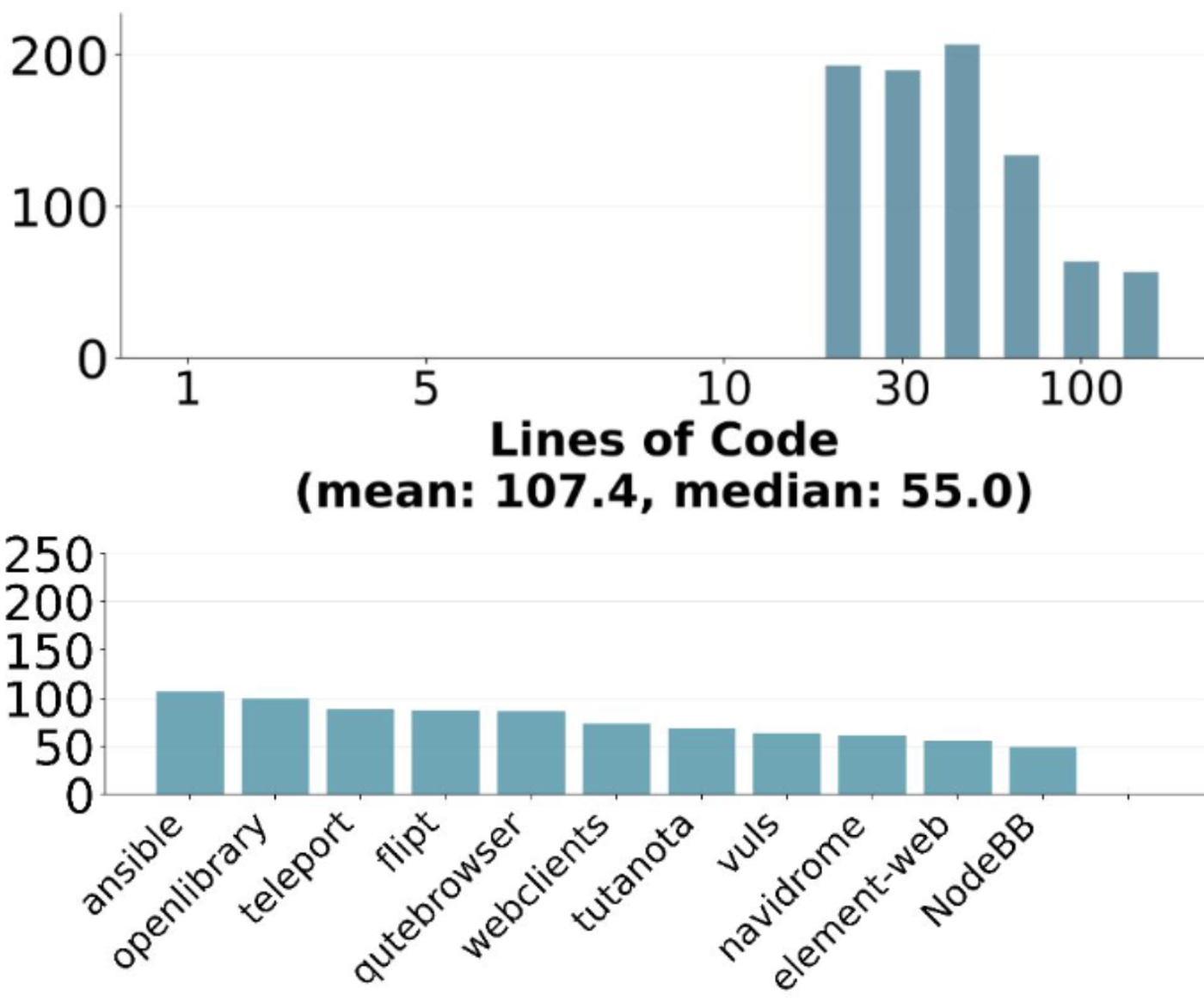
- 工业级难度:选自复杂的 B2B 服务、开发工具和消费级应用,平均每个修复涉及 107.4 行代码及 4.1 个文件。
- 人类增强说明书:不再直接使用含糊不清的 Issue 描述,而是由专家重写,确保技术挑战存在的同时问题是可解的。
性能“滑铁卢”:真实实力的体现
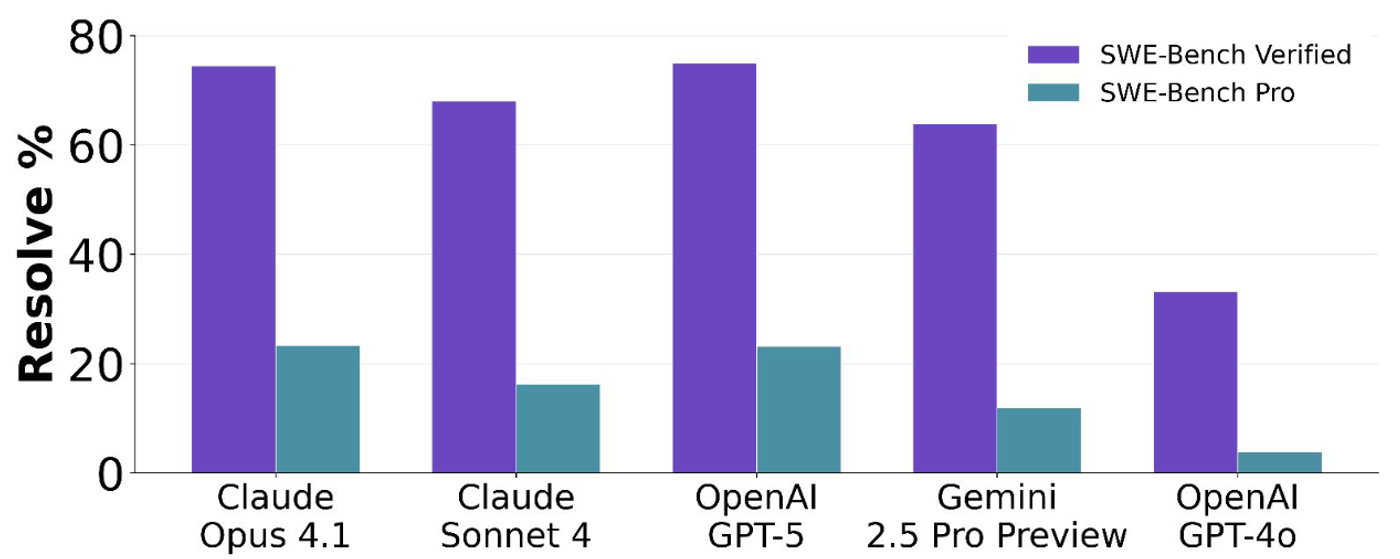
在 SWE-bench Verified 上能轻松获得 70% 以上高分的顶尖模型,在 SWE-bench Pro 面前集体遭遇了挑战。数据显示,GPT-5 和 Claude Opus 4.1 等模型的解决率骤降至 23% 左右。这表明,面对完全陌生的、长程推理的复杂工程任务,AI 仍有巨大的进步空间。
3. 2026 顶级模型横向对比
根据 Onyx AI 的全维度排名,我们可以看到 AI 编码市场的最新格局:
第一梯队:全能王者
- GPT-5.4 Pro / Claude Opus 4.6: 这两款模型在推理深度、终端操作(Terminal-Bench)和复杂修复上稳居前二。特别是在 GPT-5.4 中,其解决问题的稳定性极高,不随编程语言的改变而剧烈波动。
- Gemini 3.1 Pro: 凭借 1M+ 的超长上下文窗口,在处理大型代码仓库搜索任务时具有天然优势。
第二梯队:高性价比挑战者
- DeepSeek R1 / V3.2: 来自中国的 DeepSeek 系列在 2026 年依然是性价比之王。虽然在极其复杂的工程任务上稍逊于 Claude,但其极低的使用成本使其成为自动单元测试和中小型任务的首选。
- Kimi K2.5 / Qwen 3.5: 在逻辑推理(Coding Reasoning)方面表现亮眼,HumanEval 得分甚至逼近顶级模型。
![]()
4. 关键洞察:影响 AI 编码表现的因素
- 编程语言差异:Go 和 Python 的解决率通常最高(可达 30%+),而 JavaScript 和 TypeScript 的表现则起伏较大,这与代码库的碎片化和工具链复杂度有关。
- 代码修改量:随着任务从修复 1 个文件增加到修改 5 个以上文件,AI 的成功率呈指数级下降。长程上下文管理依然是瓶颈。
- Agent 框架的作用:单纯的模型调用已过时。如今的基准测试多采用 mini-SWE-agent 或 SWE-smith 等智能体框架,通过自动运行测试、反复迭代(Re-act)来提升解决率。
5. 总结:开发者该如何选择?
- 追求极致性能:选择 Claude Opus 4.6 或 GPT-5.4,尤其是处理涉及多个微服务的复杂 Bug 时。
- 追求成本效益:DeepSeek R1 或 Step-3.5-Flash 是大规模代码审查和简单特性开发的理想选择。
- 处理长文档/大型库:Gemini 3.1 Pro 依然是首选。
AI 程序员的时代已经开启,从 SWE-bench Pro 的数据来看,我们正处于从“AI 助手”向“AI 工程师”跨越的关键拐点。未来的基准测试将不再仅仅看模型写代码的速度,而是看它在陌生环境中、在严格的安全限制下,解决问题的真实韧性。